Empty Pipes
Never Take The First Option
The King’s Jewels Problem
A long time ago, the story goes, a hero rescues the king’s life. The elated king promises the hero one of his crown jewels as a reward. He takes out his bag of treasures and tells the hero to reach into the bag and randomly choose one. If he likes it, he can keep it. If he doesn’t, he can throw it aside and lose it forever. The hero, greedy as he is heroic, naturally wants to pick the best jewels. Looking at the bag, he judges there to be about 10 jewels inside. He stops to ponder for a second.
How should the hero proceed to maximize his chances of scoring the best jewel in the bag?
Should he just take the first one he picks or should he look at a few before deciding on one to keep? If so, how many?
We could try to answer this question analytically, but since “data science” is all the rage, why not try and answer it stochastically? If we simulate the hero’s choices, we should be able to come up with some numerically-grounded recommendation for what he should do.
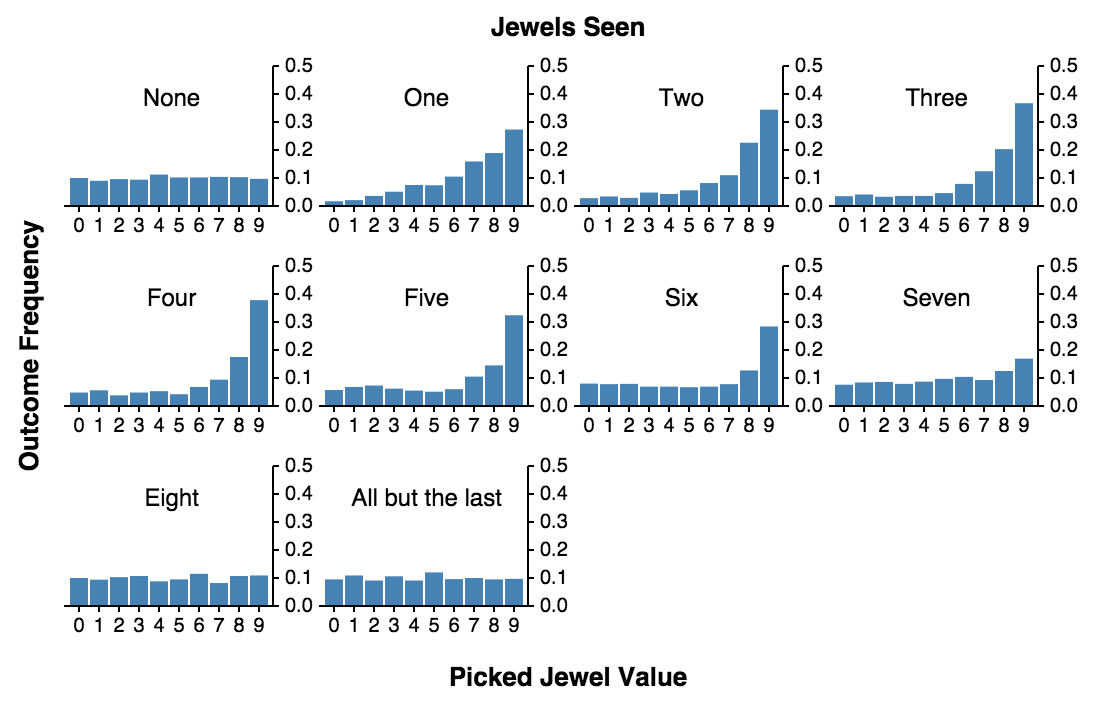
Let’s assume a simple scenario. The hero first looks at n jewels and then takes the next best jewel. If none of the jewels that come up after the first n are better, he must settle for the last.
The results are striking! If he doesn’t look at any jewels and always pick the first one, he’s equally likely to get any of the jewels. That is, the chances of picking the best one are 1/9. If he looks at one, discards it and then pick the next jewel which is better than any of the discarded, the chances of picking the best jewel increase dramatically to almost 4 / 10! In fact, the entire distribution gets skewed right and the chances of picking the second and third best jewels also significantly increase.
But the hero is after the best. From the histogram above, it’s hard to see how many he has to see and discard to maximize the chances of picking the best one. For that we can either run a simulation with lots of jewels and lots of iterations. Or we can run simulations for increasing numbers of jewels and plot how many one has to look at, to maximize his/her chances of getting the best:
What this chart shows is that the number one needs look at and throw out to maximize the chances of finding the best grows linearly with the number of jewels. The slope of the line (0.36), indicates the fraction of the total number of jewels that we should examine before picking the next best.
The red line shows how many we one should look at to maximize the average value of the kept jewel. If we try and maximize the chances of bagging the best jewel, we also increase the chances that we end up with the worst. When trying to get the highest value on average, one should look at fewer options before deciding to stick with the next best.
What if the jewels are…?
But what if the values of the jewels are not uniformly distributed? What if most jewels are average in value and only a few are either precious or worthless? Or what if most jewels have a low value with only a few true gems? The next two sections show the results when the jewels are normally distributed (mostly average) and exponentially distributed (mostly low-value).
Moral of the Story
So what should we tell our king-saving friend?
As long as there’s more than one option and you want to get the best reward possible, always discard the first third (or 1/e‘th, where e is Euler’s Number, to be more precise) of the options and then pick the next one which is better than any you have seen so far. If you want something better than average but not necessarily the best, discard fewer. Or, to put it more succintly:
Acknowledgements
- Huge thanks to Steven Rudich for introducing me to the King's Jewels problem a long time ago during a summer lecture at the Andrew's Leap program at CMU.
- Thanks to Trent Richardson for the javascript implementation of a linear regression function.